一、前言
GPU(Graphic Processing Unit)即圖形處理器,與中央處理器(Central Processing Unit,CPU)同為現今筆記型/桌上型電腦、伺服器乃至超級電腦的標準配備,其原理是利用晶片上大量算術邏輯單元(Arithmetic Logic Unit,ALU)以滿足影像處理時的高度平行計算(highly parallel computation)且計算密集(compute-intensive)需求,與CPU硬體設計上(圖1)存在顯著差異。由於無論是簡易或複雜的演算法,最終仍須透過基礎的四則運算方可利用電腦求得解析解或者近似值無異於影像處理運算方式,圖形處理器獨立製造商NVIDIA於民國95年提出結合繪圖與計算功能的G80架構圖形處理器以及整合硬體、軟體與作業平台的「統一計算架構」技術(Compute Unified Device Architecture,CUDA),使得使用者可以採單一指令多執行緒(Single-Instruction Multiple-Thread,SIMT)的執行模式撰寫高階程式語言的應用程式後,即能透過GeForce、Quadro與Tesla系列產品滿足高速平行計算需求,就此開啟GPU運算技術(GPU Computing)於科學及工程計算領域上的應用。
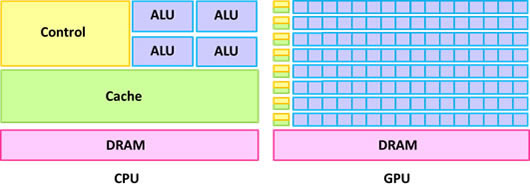 |
| 圖1 CPU與GPU硬體設計差異示意圖 |
本文首先將於NVIDIA GPU硬體發展歷程中介紹圖形處理器的硬體設計沿革並且簡介NVIDIA CUDA架構與範疇,接著藉由CUDA應用程式於作業系統的運作流程說明GPU扮演的角色,最後以Fortran與CUDA Fortran副程式說明如何開發第一支CUDA應用程式。
NVIDIA GPU硬體發展
(1)G80架構
NVIDIA的G80架構系列產品為第一代支援CUDA技術的圖形處理器,晶片架構示意圖如圖2所示,包含8組紋理處理單元叢集(Texture Processor Cluster,TPC),每組TPC主要是包含一個紋理資料快取(Cache)單元與2個串流複合處理器(Streaming Multiprocessor,SM),而各SM則有8個負責完成圖形處理器執行緒預定任務的串流處理器(Streaming Processor,SP)、一個提供SP進行資訊分享的共享記憶體(Shared Memory)以及2個用於計算如指數函數與三角函數等特殊功能單元(Special Function Unit,SFU)。
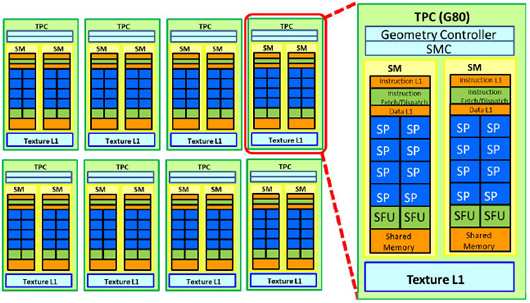 |
| 圖2 NVIDIA G80架構示意圖 |
(2)GT200架構
G80架構產品雖成功讓使用者得以利用C程式語言專注於撰寫SIMT形式平行運算應用程式,但科學研究與工程應用人員卻因其無法支援雙精確度計算而怯步。NVIDIA為此隨即於民國96年推出支援雙精確度計算能力的GT200架構,其TPC示意圖如圖3所示,除擴充每組TPC具有3個SM外,每個SM隱藏有一個雙精確度處理單元。GT200架構亦增加TPC數量為10組,使得該系列產品最高具有240個SP,高出G80架構128個SP將近一倍,因此GeForce高階產品GTX 295的每秒浮點數運算次數(FLoating-point OPerations per second,FLOPs)理論峰值可達單精確度浮點數的1,789 Giga FLOPs(GFLOPs)與雙精確度的149 GFLOPs。
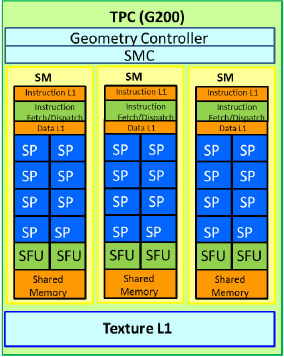 |
| 圖3 NVIDIA G200/GT200架構下的TPC示意圖 |
(3)Fermi架構
隨著應用GPU從事科學研究與數值計算的研究人員劇增,NVIDIA於民國99年發表第二代支援CUDA技術的Fermi架構圖形處理器,除了增加CUDA核心1(CUDA Core)數量與共享記憶體大小外,更實作平行資料快取技術、導入多執行緒管理引擎並且完整支援錯誤偵測與修正(Error Checking and Correcting,ECC)功能。圖4上方為Fermi架構圖形處理器示意圖,可知為單一晶片配置一個L2快取單元,整合最高16組具L1快取單元之SM,透過6個64位元(bit)寬度通道(即記憶體介面寬度為384 bit)使用6個記憶體分區最高達6 GiB的動態隨機存取記憶體(Dynamic Random Access Memory,DRAM)。
由於Fermi架構的SM配置有32個包含一個整數ALU與一個浮點數算術邏輯單元(Floating Point Unit,FPU)的CUDA核心、4個特殊功能單元、16個載入/儲存單元(LD /ST)、以及2個執行緒束排程器(warp scheduler)與2個指令發送單元(instruction dispatch unit),各排程器可如圖5所示,獨立選擇執行緒束(warp)並指派單一工作指令給16個CUDA核心進行作業。為大幅提升雙精確度浮點數運算能力,Fermi架構設計SM可同時處理16個雙精確度浮點數運算,並且實作IEEE754-2008浮點算術標準而具有於一次CUDA核心運作中整合雙精確度浮點數乘法與加法運算的功能(Fused Multiply-Add,FMA),統以增速因子2代表。
NVIDIA圖形處理器每秒浮點數運算次數理論峰值的計算方式為「串流複合處理器數x浮點數處理單元數x增速因子xCUDA核心計算頻率」,而記憶體理論頻寬計算方式為「記憶體通道數x記憶體時脈頻率x記憶體介面寬度位元/8」。以具備14組SM的Tesla C2050產品為例,因CUDA核心計算頻率為1.15 GHz,記憶體時脈頻率為1.5 GHz,使得每秒單/雙精確度浮點數運算次數分別可達14x32x2x1.15=1,030.4與14x16x2x1.15=515.2(GFLOPs)的理論峰值,而記憶體理論頻寬則為2x1.5x384/8=144(GiB/sec)。
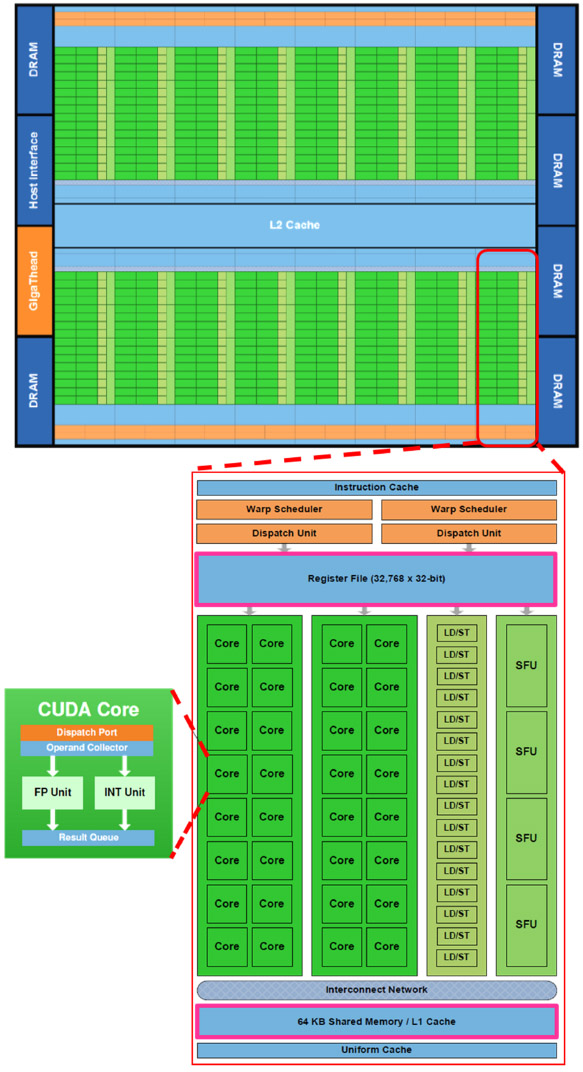 |
| 圖4 NVIDIA Fermi架構示意圖 |
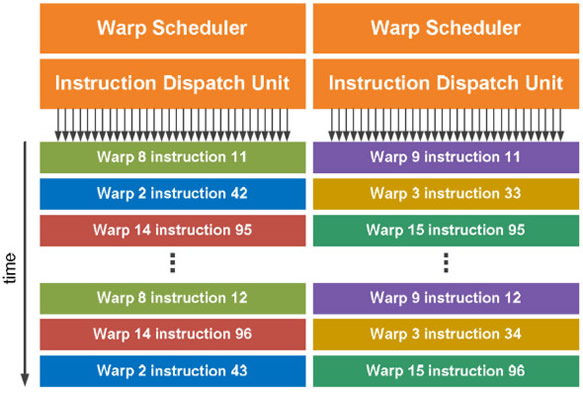 |
| 圖5 NVIDIA Fermi架構SM工作發送示意圖 |
(4)Kepler架構
NVIDIA於民國101年中旬發表第三代支援CUDA技術的Kepler架構圖形處理器(圖6上方),除係以Fermi架構為基礎增加串流複合處理器2上的CUDA核心數達6倍、增加各項記憶體大小並且改進L1與L2快取組態功能,更重要的是新增得以與多個CPU建立最高32個工作佇列的「Hyper-Q」功能、允許圖形處理器執行緒自行新增工作指令的「Dynamic Parallelism」功能以及與本機或相異主機的圖形處理器直接交換資料的「GPU Direct」功能等三項特色,使得Kepler架構圖形處理器極具強大的多工處理能力,亦使CUDA應用程式開發能更符合實際物理問題模擬需求。
圖6下方所示為Kepler架構的SMX示意,設計有192個具ALU與FPU各一的CUDA核心、64個專屬的雙精確度浮點數處理單元(DP unit)、32個特殊功能單元、32個載入/儲存單元以及4個執行緒束排程器及8個指令發送單元。SMX的執行緒束排程器除與Fermi架構的SM同樣可獨立選擇執行緒束外,更透過2個指令發送單元指派2個獨立工作指令給該執行緒束進行作業,並且允許同時進行雙精確度浮點數運算與其他工作指令(圖7)。
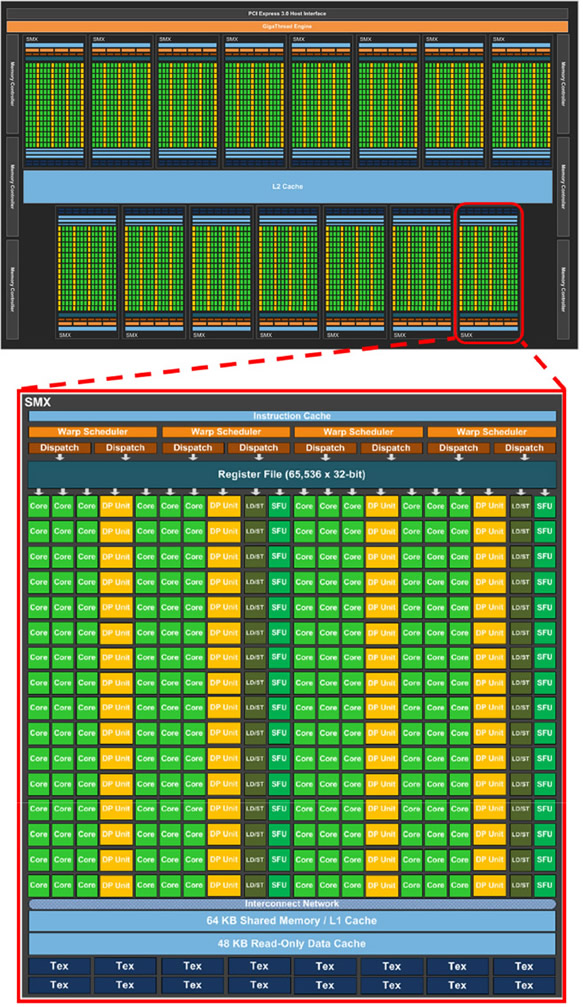 |
| 圖6 NVIDIA Kepler架構示意圖 |
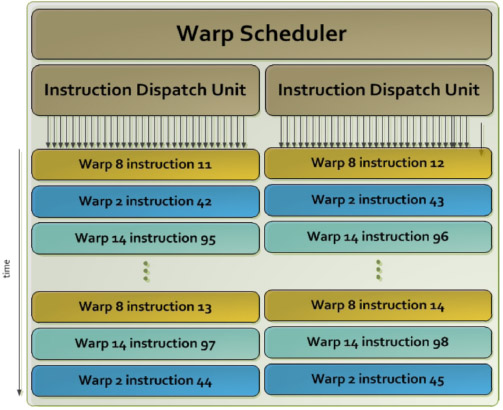 |
| 圖7 NVIDIA Kepler架構SMX工作發送示意圖 |
以具備15組SMX的Tesla K40產品為例,CUDA核心計算頻率為745 MHz,記憶體時脈頻率為3.0 GHz,記憶體介面寬度為384 位元,因此每秒單/雙精確度浮點數運算次數分別可達4.29 與1.43 TFLOPs(Tera FLOPs)的理論峰值,並且記憶體理論頻寬可達288 GiB/sec。圖8與圖9分別為NVIDIA GPU與Intel CPU之每秒浮點數運算次數理論峰值比較與記憶體理論頻寬比較時序,可知截至2013年8月Intel發表的Ivy Bridge中央處理器為止,圖形處理器的運算能力均已高出中央處理器甚多。
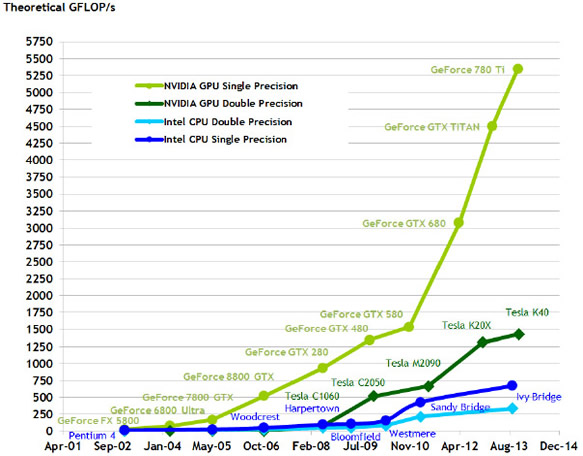 |
| 圖8 NVIDIA GPU與Intel CPU之每秒浮點數運算次數理論峰值比較 |
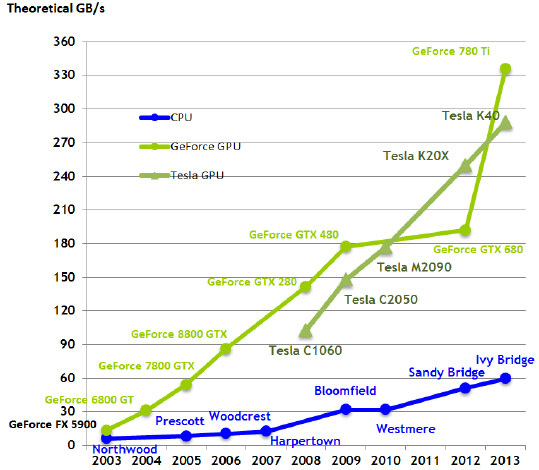 |
| 圖9 NVIDIA GPU與Intel CPU之記憶體理論頻寬比較 |
(5)圖形處理器記憶體
NVIDIA 圖形處理器提供了包含全域記憶體(global memory)、常數記憶體(constant memory)、材質記憶體(texture memory)、共享記憶體、區域記憶體(local memory)以及暫存器(register)等6種不同類型的記憶體,其所在位置、存取屬性、可視範疇與生命周期如表1所示。
全域、常數、材質與區域記憶體皆位於DRAM上(稱為off-chip位置),可供不同執行緒區塊中的各執行緒使用。全域記憶體容量最大,所有執行緒都能讀寫(R/W)全域記憶體,適合用於儲存大量資料,並為主機端上傳與下載圖形處理器端資料管道,在Fermi與Kepler架構中可透過L1與L2的快取加速存取速度;常數記憶體與材質記憶體,僅供執行緒讀取,可加速資料的存取,其中常數記憶體容量約數十KiB,資料存取速度約為全域記憶體的10倍;材質記憶體常用於影像處理時儲存影像原始資料需透過的特殊存取方式來達成;而區域記憶體提供執行緒區塊中每一個執行緒自己存取的記憶體空間,可提供讀取但速度較暫存器稍慢。
共享記憶體與暫存器皆位於SM或SMX上(稱為on-chip位置),共享記憶體執行時期提供一個執行緒區塊內所有執行緒讀寫,容量約數十KiB,提供區塊中每個執行緒存共享或交換資料,執行緒存取資料速度約為存取全域記憶體的100倍;暫存器如同於CPU暫存器,執行緒存取資料速度約與共享記憶體相當,用以儲存執行緒執行計算程序中區域變數。
| 表1 NVIDIA 圖形處理器記憶體類型與特性一覽表 |
| 類型 |
位置 |
存取屬性 |
可視範疇 |
生命週期 |
| local |
off-chip |
Read/Write |
one thread |
thread |
| global |
Read/Write |
all threads + host |
application |
| constant |
Read |
all threads + host |
application |
| texture |
Read |
all threads + host |
application |
| shared |
on-chip |
Read/Write |
all threads in a block |
block |
| register |
Read/Write |
one thread |
thread |
|
NVIDIA CUDA技術
「統一計算架構」(以下稱CUDA技術)為NVIDIA針對使用圖形處理器達成通用目的運算需求(GPGPU)所提出的解決方案,包含提供使用者使用高階程式語言撰寫CUDA應用程式的發展環境,以及提供應用程式正確執行的軟、硬體環境。如圖10所示,CUDA技術包含粉紅色區塊所示之支援CUDA技術的圖形處理器計算引擎、作業系統、驅動程式與執行緒平行運作指令集(Parallel Thread eXecution,PTX)等4個部分的軟、硬體環境,以及提供使用者利用C、C++、Fortan、JAVA、Python、OpenCL與Direct Compute等高階程式語言開發應用程式的執行時期函式庫(Runtime API)與驅動程序API的綠色與藍色區塊。此外,CUDA技術亦含括如圖11中灰色區塊所示的cuFFT、cuBLAS、CULA…等等數學函式庫與中介層,大幅降低使用者開發CUDA應用程式門檻,有效縮短開發時程並提升正確性。
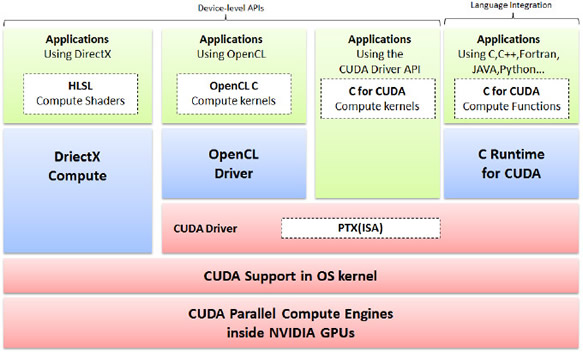 |
| 圖10 CUDA技術軟、硬體環境示意圖 |
 |
| 圖11 CUDA技術之應用程式開發環境 |
CUDA應用程式運作流程
CUDA應用程式於作業系統運作時係採GPU協同CPU作業方式,運作流程包含圖12所示的1.CPU複製系統主記憶體資料到GPU、2.CPU啟動圖形處理器上的CUDA核心並交付工作、3.大量CUDA核心同時執行計算程序(kernel)以進行平行運算,以及4.CPU將計算結果複製回系統主記憶體等四個步驟。
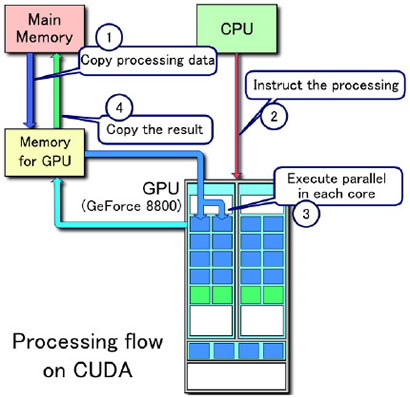 |
| 圖12 GPU協同CPU作業運作流程 |
將上述步驟3整合執行緒存取不同類型記憶體的運作方式如圖13所示,綠色代表執行緒群組,內含多個黃色執行緒區塊,而一個執行緒區塊則為多個紫色執行緒組成。步驟3中,各CUDA核心係由一個圖形處理器執行緒所控制,該執行緒自CPU啟動之工作交付編組(步驟2)中取得唯一編號後,即依此讀取由CPU複製到GPU全域記憶體、常數記憶體與材質記憶體的資料(步驟1),再依工作指令儲存於專屬該執行緒的暫存器、區域記憶體(粉紅色區塊)或由執行緒區塊共享資訊的共享記憶體(藍色區塊)內,並於後續工作指令完成時將結果儲存於全域記憶體,最終並由CPU取回(步驟4)。
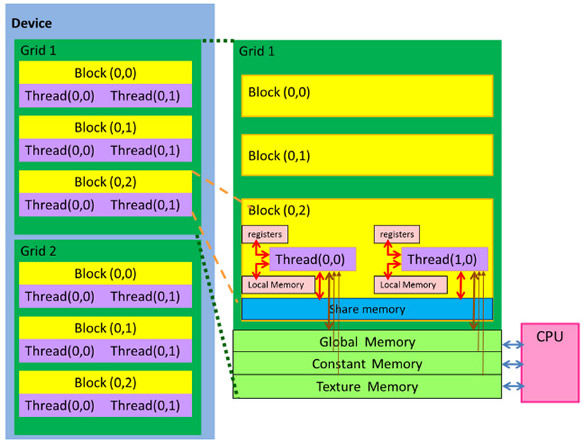 |
| 圖13 CUDA應用程式執行時期之執行緒(紫色)、執行緒區塊(黃色)與執行緒群組(綠色)階層關係與不同類型記憶體的存取方式 |
CUDA應用程式開發入門
著手CUDA應用程式開發的第一步是到NVIDIA官網依圖形處理器下載並安裝CUDA Driver 3、包含NVCC(NVIDIA C Compiler)編譯器與函式庫的CUDA Toolkit 4與包含許多範例程式的CUDA SDK。NVCC為NVIDIA開發用以轉換C語言擴充定義的編譯器,作用類似標準C語言編譯器的前處理器,提供C / C++語言使用者於慣用的程式編撰環境中無痕開發CUDA應用程式。
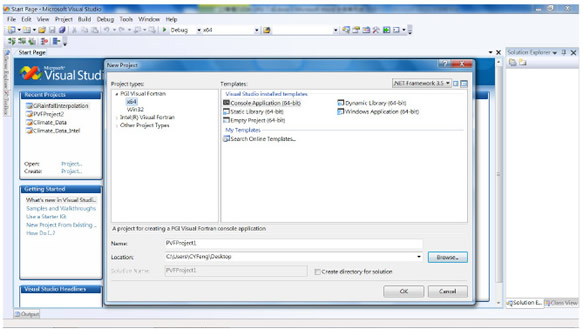
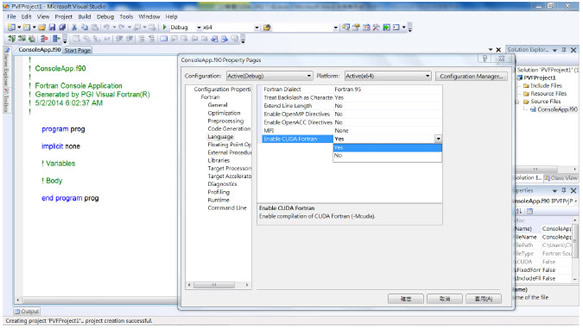
PGI (The Portland Group)同樣採用擴充標準Fortran語言的方式,於民國99年發表與NVIDIA合作開發的CUDA Fortran提供Fortran語言使用者開發CUDA應用程式。此外,PGI亦更進一步發展遵循OpenACC規範的PGI Accelerator指令式語法,方便使用者可在原有Fortran程式碼適當位置加入如!$acc region與!$acc end region的指令,由CUDA Fortran編譯器自動轉譯並編譯為CUDA應用程式以縮短開發時程。以下簡述於Microsoft Visual Studio 2008以PGI CUDA Fortran開發CUDA應用程式步驟:
1. 建立新方案:選取PGI Visual Fortran,建立新專案
2. 選取專案/屬性/Fortran/Language:打開Enable CUDA Fortran選項
3. CUDA程式碼撰寫
4. CUDA程式碼編譯
CUDA技術設計圖14所示的執行緒(thread)、執行緒區塊(thread block)與執行緒群組(grid)三層編號系統,提供使用者管理CUDA應用程式於執行期產生之圖形處理器執行緒對應於CUDA核心(圖中thread processor)、串流複合處理器(圖中multiprocessor)與串流複合處理器群組(圖中device)三層實體硬體架構運作。
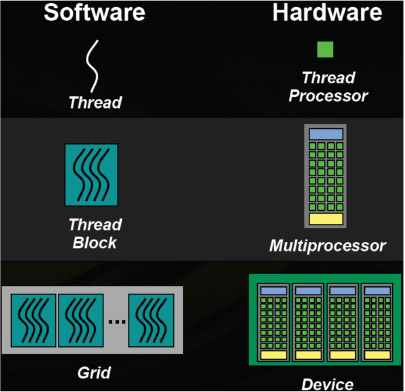 |
| 圖14 NVIDIA CUDA技術執行緒管理方式與圖形處理器硬體對應關係 |
表2所示之簡易向量相加運算計算程序Fortran程式碼與CUDA Fortran程式碼。其中“Attributes(global)”代表此副程式將由CPU啟動CUDA核心執行,“use cudafor”代表使用CUDA內建變數定義模組,“device”代表變數宣告並儲存於圖形處理器記憶體,“value”代表CPU僅傳遞參數值給CUDA計算核心,而“blockidx%x”與“threadidx%x”則分別代表執行緒區塊與執行緒於x方向上的編號。當CPU設定運算所需啟動的執行緒區塊數目與執行緒數目啟動CUDA Fortran副程式後,每個被啟動的執行緒將執行相同之Vaddkernel計算程序,並透過第6列計算取得固定且唯一編號i,相加向量A與向量B中第i元素而為向量C。對照表Fortran程式碼第5~7列可知,原有迴圈“do i=1,N”隱藏於個別執行緒相加自身編號相關資料的過程,稱為隱式迴圈。
| 表2 簡易向量相加Fortran程式碼範例 |
| 列 |
Fortran |
CUDA Fortran |
1
2
3
4
5
6
7
8 |
Subroutine host_vadd(A,B,C,N)
real(4):: A(N), B(N), C(N)
integer:: N
integer:: I
do i=1, N
C(i)= A(i) + B(i)
end do
End subroutine host_vadd |
Attributes(global) subroutine Vaddkernel(A,B,C,N)
use cudafor
real(4), device:: A(N), B(N), C(N)
integer, value:: N
integer:: I
i = (blockidx%x-1)*32 + threadidx%x
if ( i <= N ) C(i)= A(i) + B(i)
End subroutine vaddkernel |
|
結語
NVIDIA圖形處理器與CUDA技術已然成為平行運算領域的生力軍,可輕鬆讓桌上型電腦瞬間擁有高於中央處理器數倍運算能力的計算資源,搖身成為研究人員專屬的個人超級電腦,使得符合高度平行計算與計算密集特性的應用問題均可縮短數十倍甚至數百倍以上的計算時間。
當然,研究人員必須依照應用問題的演算法特性,修改程式碼而能妥善使用前述不同類型的GPU記憶體,考量達成「資料合併存取」(Memory coalescing)、避免「共享記憶體記憶庫衝突」(Bank conflicts)與避免「全域記憶體記憶體分區衝突」(Partition camping)等三種現象,方能顯著提升應用程式計算效能。以多采科技開發的二維淺水波數值模式為例,以NVIDIA Tesla K20c與Intel® Xeon® X5650 2.66GHz為計算資源模擬曾文水庫潰壩後800秒情境,兩者所需時間分別為140.11秒及60,919秒,加速比可達434倍,使得全二維即時淹水模擬已非遙不可及的夢想!
參考文獻
- NVIDIA CUDA Architecture
- NVIDIA CUDA Best Practices Guide
- NVIDIA GeForce 8800 GPU Architecture Overview
- NVIDIA’s Next Generation CUDA Compute Architecture Fermi
- NVIDIA’s Next Generation CUDA Compute Architecture Kepler GK110
- http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
- 林俊淵、周嘉奕、林郁翔、李昇達、陳昱蓉、黃宣穎與李天齡,(2012)。CUDA輕鬆上手-新世代GPU應用技術(初版)。松崗資產管理股份有限公司。
1 即第一代架構中的SP,自Fermi架構起正式命名為CUDA核心
下一篇
|